| gamersfan | Дата: Четверг, 26.Ноября.2015, 20:23 | Сообщение # 1 |
 Главный админ
Группа: Администраторы
Сообщений: 1263
Репутация: 8
Статус: Offline
| Уже прошедшая Supercomputing Conference ’15 продолжает служить источником весьма интересной информации. На этот раз речь пойдёт об одном из самых амбициозных проектов NVIDIA — архитектуре Pascal и процессорах на её основе. Мы намеренно опускаем эпитет «графический», поскольку видеокарты на базе Pascal, конечно, будут выпущены, но станут лишь побочной ветвью, а основной целью NVIDIA является доминирование на рынке супервычислений (HPC), и с учётом этой цели Pascal и разрабатывается. Кроме того, компания поделилась информацией и о будущем наследнике Pascal, проекте Volta.
Уже известно, что процессоры Pascal будут выпускаться с использованием 16-нм технологических норм, и на SC15 NVIDIA подтвердила использование техпроцесса 16-нм FinFET+. О том, на какой именно фабрике будут производиться новые чипы, компания умолчала, но имя главного контрактного поставщика было названо — TSMC. Неудивительно, ведь первые образцы процессора GP100 были получены именно c помощью вышеупомянутого техпроцесса TSMC. Поэтому не исключен сценарий, в котором мы увидим анонс Pascal уже в первой половине 2016 года. Таким образом, ранние предсказания о том, что выпуском Pascal может заняться и Samsung, не оправдались.
Плотность упаковки транзисторов, как мы уже знаем, удвоена в сравнении с Maxwell GM200, так что Pascal будет состоять из примерно 16 ‒ 17 миллиардов активных элементов. В сравнении с технологией 20SoC, техпроцесс 16FF+ может обеспечить до 40 % прироста производительности и до 60 % выигрыша в уровне энергопотребления, что для таких монстров, как GP100, является очень важным фактором. Итак, пока мы знаем о GP100 следующие факты:
- Поддержка возможностей DirectX 12 уровня 12_1 или выше;
- Наследник GM200, будет использован в новых флагманских моделях видеокарт;
- Производится с использованием техпроцесса TSMC 16-нм FinFET+;
- Состоит из 16 ‒ 17 миллиардов транзисторов;
- Впервые получен в кремнии ещё в июне 2015 года;
- Получит 4 сборки HBM2 4-Hi, объём памяти — 16 Гбайт в потребительской версии, 32 Гбайт в профессиональном варианте;
- Ширина интерфейса памяти 4096 бит;
- Получит высокоскоростную шину NVLink;
- Будет поддерживать вычислительные нагрузки смешанного характера: FP16, 32 и 64;
- Производительность в режиме FP16 вдвое выше, нежели в режиме FP32, полноценная поддержка FP64;
- Производительность в режиме FP64 свыше 4 терафлопс (см. вышеприведённую диаграмму);
- Производительность в режиме FP32 свыше 10 терафлопс.
А в следующем поколении процессоров под кодовым названием Volta NVIDIA планирует достичь цифр в районе 7 терафлопс, что очень впечатляет: новейший 14-нм ускоритель Intel Knight’s Landing развивает в режиме FP64 лишь несколько более 3 терафлопс, а самый мощный на сегодня двухпроцессорный ускоритель NVIDIA Tesla K80 — всего 2,91 терафлопса, да и то в турборежиме.

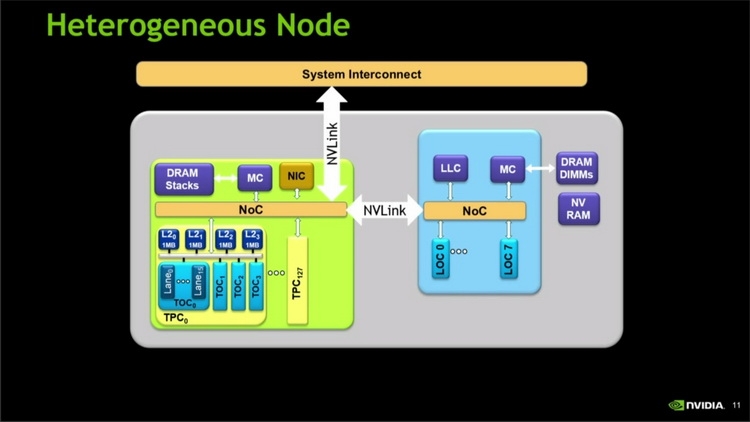
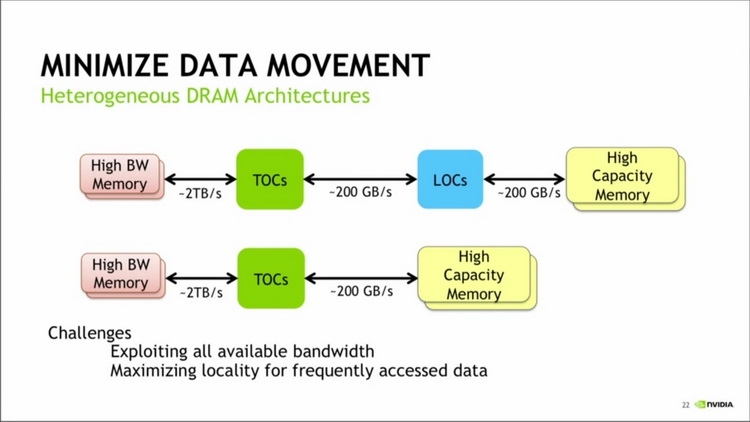 Даже в случае с обычными мощными видеокартами проблема энергопотребления и тепловыделения стоит довольно остро. Но для разработчиков суперкомпьютеров она, наверняка, является одной из тем ночных кошмаров. Быстрая память таким системам просто необходима, но HBM2 в Pascal и Volta при пропускной способности 1,2 Тбайт/с добавляет целых 60 ватт к энергопакету процессора. Даже HBM1, использующаяся в AMD Fiji, и то добавляет 25 ватт к потреблению ядра. В дальнейшем планируется достичь скоростей в районе 2 Тбайт/с, и тут-то и начинается ужас: пропускная способность HBM2 на уровне 2,5 Тбайт/с обойдётся в 120 ватт на процессор, а при повышении ПСП до 3 Тбайт/с этот показатель увеличится до 160 ватт. Умножьте это на количество процессоров в узле и на количество узлов в суперкомпьютере — и будет понятно, какую цену приходится платить за высокую производительность подсистемы памяти. 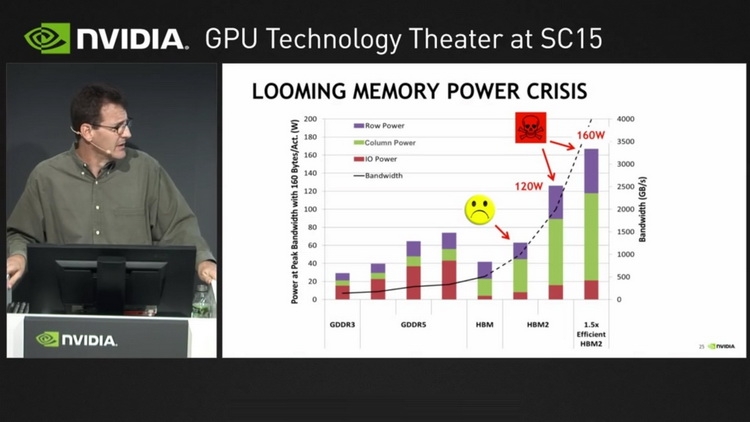 В ближней перспективе это приемлемо, поскольку HBM2 является на сегодня оптимальным типом памяти для решений такого рода. Но к 2020 году, с появлением новых, ещё более производительных процессорных архитектур, кризис энергопотребления многослойной памяти может обостриться до предела. NVIDIA это понимает, поэтому, по всей видимости, уже ведёт исследования в области создания новой, высокопроизводительной, но при этом экономичной архитектуры памяти. Какой она будет, сейчас сказать крайне сложно. Даже в общих чертах неясно, как сохранить скорости в районе единиц или даже десятков терабайт в секунду и удержать при этом уровень энергопотребления в мало-мальски приемлемых рамках. 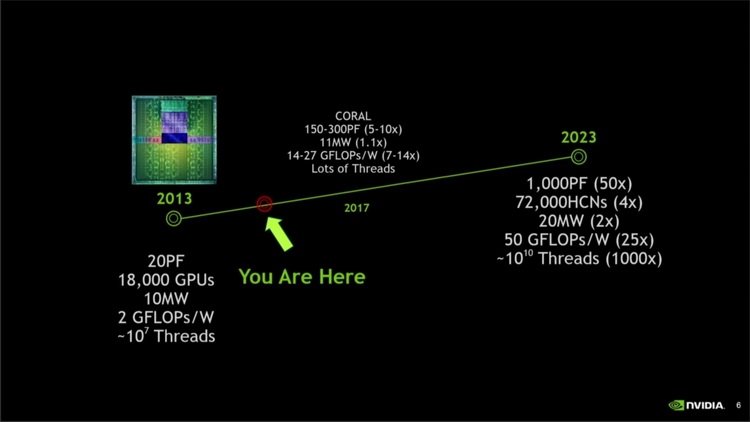 |
| |
| |








